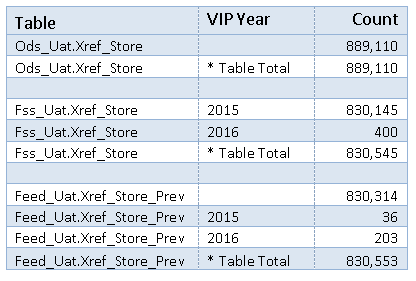
Just a picture of 99% of the date variations listed in the book, although I'm saving timestamps for another post.
The Easy Way
Select To_Char(Sysdate,'DL' ) DL /* long date */
, To_Char(Sysdate,'DS' ) DS /* short date */
, To_Char(Sysdate,'TS' ) TS /* short time */
, To_Char(Sysdate,'DS TS') DSTS /* short date, time */
From Dual;
DL | DS | TS | DSTS
------------------------- | -------- | ---------- | --------------------
Saturday, August 06, 2011 | 8/6/2011 | 9:27:37 AM | 8/6/2011 09:27:37 AM
Day
Select To_Char(Sysdate,'DAY' ) "DAY" /* Name (Uppercase) */
, To_Char(Sysdate,'Day' ) "Day" /* Name (Title case) */
, To_Char(Sysdate,'DY' ) "DY" /* Abbreviated (Uppercase). */
, To_Char(Sysdate,'Dy' ) "Dy" /* Abbreviated (Title case). */
, To_Char(Sysdate,'D' ) "D" /* Day of week (1-7). */
, To_Char(Sysdate,'DD' ) "DD" /* Day of month (1-31). */
, To_Char(Sysdate,'fmDD' ) "fmDD" /* Day of month (1-31) zero suppress */
, To_Char(Sysdate,'DDD' ) "DDD" /* Day of year (1-366). */
, To_Char(Sysdate,'DDsp' ) "DDsp" /* spell out (Uppercase)*/
, To_Char(Sysdate,'Ddsp' ) "Ddsp" /* spell out (Titlecase)*/
, To_Char(Sysdate,'DDth' ) "DDth" /* ordinal (Uppercase) */
, To_Char(Sysdate,'Ddth' ) "Ddth" /* ordinal (Title case) */
, To_Char(Sysdate,'fmDdth') "fmDdth" /* ordinal zero suppress */
, To_Char(Sysdate,'J' ) "J" /* Julian:# days since 1/1/4712BC */
From Dual;
DAY | Day | DY | Dy | D | DD | fmDD | DDD | DDsp | Ddsp | DDth | Ddth | fmDdth | J
-------- | -------- | --- | --- | - | -- | ---- | --- | ---- | ---- | ---- | ---- | ------ | -------
SATURDAY | Saturday | SAT | Sat | 7 | 06 | 6 | 218 | SIX | Six | 06TH | 06th | 6th | 2455780
Embed in Format - / , ; : . "text"
Select To_Char(Sysdate,'"Day": Dy, "Month": Month')
From Dual;
TO_CHAR(SYSDATE,'"DAY":DY,
--------------------------
Day: Sat, Month: August
Century
Select To_Char(Sysdate,'AD') "AD" /* AD or BC */
, To_Char(Sysdate,'A.D.')"A.D." /* A.D or B.C. */
, To_Char(Sysdate,'B.C.')"B.C." /* A.D or B.C. */
From Dual;
AD | A.D. | B.C.
-- | ---- | ----
AD | A.D. | A.D.
Month /* use fm in front to remove padding */
Select To_Char(Sysdate,'MM') "MM" /* 01-12 */
, To_Char(Sysdate,'Month') "Month" /* Name padded with blanks to widest name */
, To_Char(Sysdate,'fmMonth') "fmMonth"/* Name not padded */
, To_Char(Sysdate,'MONTH') "MONTH" /* NAME padded with blanks to widest name */
, To_Char(Sysdate,'Mon') "Mon" /* Abbreviated name (title case) */
, To_Char(Sysdate,'MON') "MON" /* Abbreviated name (uppercase) */
, To_Char(Sysdate,'RM') "RM" /* Roman numeral month */
From Dual;
MM | Month | fmMonth | MONTH | Mon | MON | RM
-- | --------- | ------- | ------ | --- | --- | ----
08 | August | August | AUGUST | Aug | AUG | VIII
Week
Select To_Char(Sysdate,'WW') "WW" /* Week of year (1-53) where week 1 = 1/1 to 1/7. */
, To_Char(Sysdate,'WWth') "WWth" /* Week of year (1ST-53RD) */
, To_Char(Sysdate,'Wwth') "Wwth" /* Week of year (1st-53rd) */
, To_Char(Sysdate,'WWsp') "WWsp" /* Week of year spelled out in caps */
, To_Char(Sysdate,'Wwsp') "Wwsp" /* Week of year spelled out in title case*/
, To_Char(Sysdate,'WWthsp') "WWthsp"/* Week of year (1st-53rd) spelled out*/
, To_Char(Sysdate,'W') "W" /* Week of month (1-5) where week 1 = 1st to 7th*/
, To_Char(Sysdate,'Wth') "Wth" /* Week of month (1st-5th) */
From Dual;
WW | WWth | Wwth | WWsp | Wwsp | WWthsp | W | Wth
-- | ---- | ---- | ---------- | ---------- | ------------- | - | ---
32 | 32ND | 32nd | THIRTY-TWO | Thirty-Two | THIRTY-SECOND | 1 | 1st
Quarter
Select To_Char(Sysdate,'Q') "Q" /* Quarter of year (1=Jan-Mar, 2=Apr-Jun, etc)*/
, To_Char(Sysdate,'Qth') "Qth" /* Quarter of year (1st - 4th */
, To_Char(Sysdate,'Qsp') "Qsp" /* Quarter of year (One - Four) */
, To_Char(Sysdate,'Qthsp') "Qthsp" /* Quarter of year (First - Fourth) */
From Dual;
Q | Qth | Qsp | Qthsp
- | --- | ----- | -----
3 | 3rd | Three | Third
Year
Select To_Char(Sysdate,'Year') "Year" /* Spell out year */
, To_Char(Sysdate,'RR') "RR" /* store 20th century dates in 21st using 2 digits */
, To_Char(Sysdate,'RRRR') "RRRR" /* Round for 4 or 2. If 2, provides the same return as RR. */
, To_Char(Sysdate,'Y,YYY') "Y,YYY" /* Year with comma */
, To_Char(Sysdate,'YEAR') "YEAR" /* spelled out */
, To_Char(Sysdate,'YYYY') "YYYY" /* 4-digit year */
, To_Char(Sysdate,'YYY') "YYY" /* Last 3 digits */
, To_Char(Sysdate,'YY') "YY" /* Last 2 digits */
, To_Char(Sysdate,'Y') "Y" /* Last digit */
From Dual;
Year | RR | RRRR | Y,YYY | YEAR | YYYY | YYY | YY | Y
------------- | -- | ---- | ----- | ------------- | ---- | --- | -- | -
Twenty Eleven | 11 | 2011 | 2,011 | TWENTY ELEVEN | 2011 | 011 | 11 | 1
Time
Select To_Char(Sysdate,'AM') "AM" /* Meridian indicator */
, To_Char(Sysdate,'a.m.') "a.m." /* Meridian indicator */
, To_Char(Sysdate,'HH') "HH" /* Hour of day (1-12). */
, To_Char(Sysdate,'fmHH') "fmHH" /* Hour of day (1-12). */
, To_Char(Sysdate,'HH24') "HH24" /* Hour of day (0-23). */
, To_Char(Sysdate,'MI') "MI" /* Minute (0-59). */
, To_Char(Sysdate,'SS') "SS" /* Second (0-59). */
, To_Char(Sysdate,'SSSSS') "SSSSS"/* Seconds past midnight (0-86399)*/
From Dual;
AM | a.m. | HH | fm | HH | MI | SS | SSSSS
-- | ---- | -- | -- | -- | -- | -- | -----
AM | a.m. | 09 | 9 | 09 | 27 | 37 | 34057